QuantLens Data Platform
A personal finance data dashboard that runs on a €6/month server, proving you don't need expensive enterprise software to analyze stock markets. (Under Active Development)
Status: This is an internal research initiative under active development.
Overview
QuantLens is a personal finance data dashboard built to prove a point: you don't need expensive enterprise software (like Databricks or Snowflake) to analyze stock market data. We built a complete data platform that runs on a server costing just €6/month.
This project serves as a reference for small teams and solo engineers who want powerful data tools without the complexity and cost of typical "Big Data" solutions.
The Philosophy: Control vs. Cost
Enterprise tools like Databricks, Snowflake, or Azure Fabric are standard for large organizations. They solve the problem of scaling to petabytes and managing hundreds of engineers. However, for small teams or deep technical R&D shops, these tools are often overkill. They introduce significant billing overhead and vendor lock-in for workloads that simply do not require distributed clusters.
We believe that for high-performance, focused engineering teams, self-hosted infrastructure provides the ultimate balance: full control, maximum data sovereignty, and extreme cost-effectiveness. You pay for the metal, not the markup.
The Solution
We architected a fully self-managed stack running on a standard Hetzner Cloud VM (CAX21: 4 vCPU, 8GB RAM). This setup costs approximately €6/month, demonstrating that you do not need a five-figure cloud bill to have a professional data lakehouse.
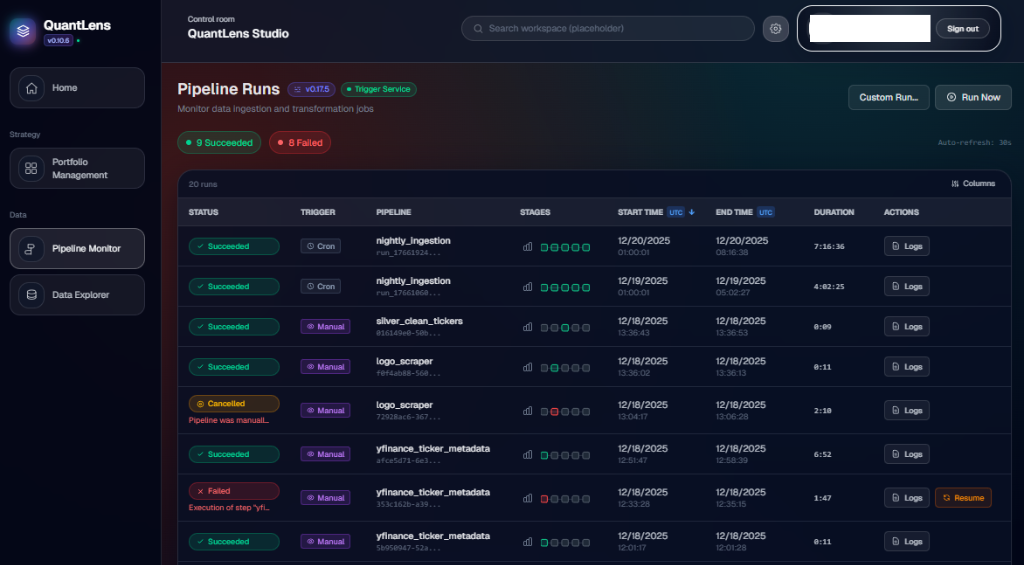
1. "Control Room" Frontend
We built a custom dashboard inspired by the operational clarity of Azure Data Factory's monitoring view.
- Pipeline History: Provides a clear, temporal view of all Dagster runs, allowing for instant debugging of failures.
- Data Explorer: A lightweight query interface allowing users to explore the Delta Lake directly using DuckDB. This brings the "Query Editor" experience of big platforms to local files.
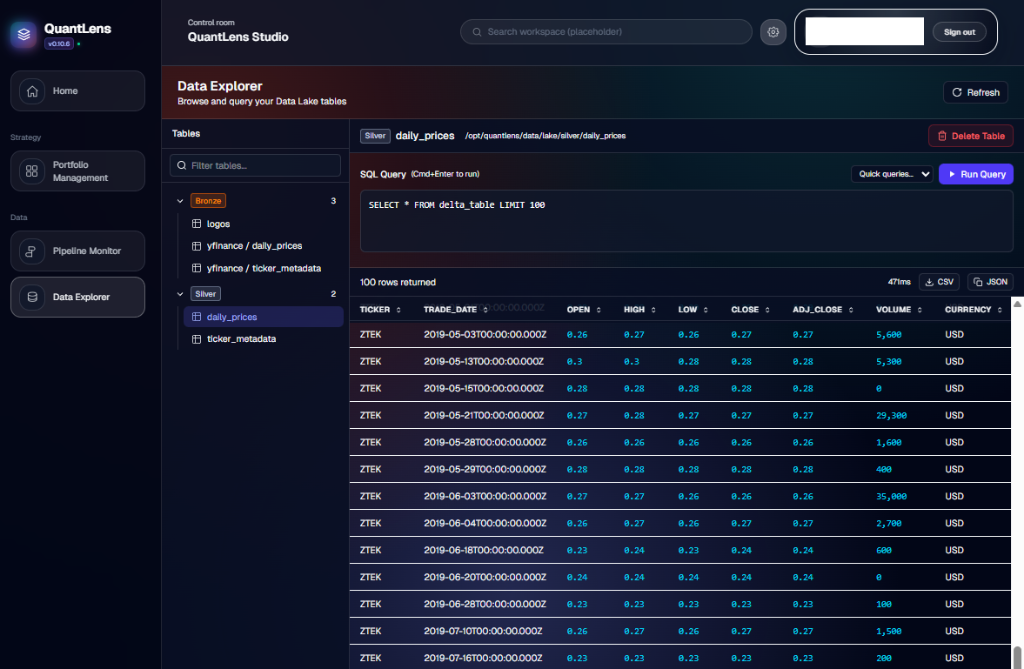
2. Data Storage: The Local Lakehouse
We implemented a full Delta Lake architecture, but instead of using expensive cloud object storage (S3), we hosted it locally on the VM's NVMe drive under /data/lake.
- Architecture: A standardized Bronze/Silver/Gold medallion architecture ensures data quality and lineage.
- Performance: By keeping compute (DuckDB) and storage (Delta Tables) on the same machine, we eliminate network latency entirely.
- Protocol: We leverage the open-source Delta Lake protocol for ACID transactions and time-travel, giving us enterprise-grade reliability on a local filesystem.
3. High-Efficiency Engine: Why DuckDB?
A core architectural decision was selecting the compute engine. The industry standard for years has been Apache Spark. However, we identified a shift in the data landscape.
The Spark vs. DuckDB Trade-off
In 2015, vertical scaling was hard, and RAM was expensive. If you had 100GB of data, you often needed a cluster. Today, a single node with NVMe drives and reasonable RAM can verify massive datasets.
For workloads under 1TB/day (which covers 99% of use cases), the complexity of managing a Spark cluster (JVM tuning, worker nodes, shuffling) is an unnecessary tax. We aligned with the industry trend favoring DuckDB for single-node processing. It allows us to process millions of rows of financial data in-memory with vectorized execution, avoiding the network overhead of distributed systems entirely.
4. Orchestration & Quality
- Dagster: Manages complex dependency graphs and pipeline execution. We prefer its asset-based definition over Airflow's task-based approach.
- dbt (Data Build Tool): Handles SQL transformations and automated testing.
- Docker: Containerizes every step to ensure consistent execution environments.
5. Infrastructure as Code
The entire platform is defined in code.
- Ansible: Automates the provisioning and configuration of the Linux server.
- Self-Healing: The system is designed to recover automatically from failures, minimizing maintenance overhead.
Note: DevOps Highlight: Self-Healing Infrastructure The platform runs on "ephemeral runners" that automatically reset state between jobs. Using Ansible, we provision the environment from scratch in minutes, ensuring no "configuration drift" occurs over months of operation.
Architectural Considerations & Trade-offs
"What about the CAP theorem? What happens when the VM goes down?" - and that's the right question to ask.
The Elephant in the Room: Single-Node Reliability
Let's be honest about what this architecture trades away:
- Partition Tolerance (P): With a single VM, there's no partition to tolerate - but there's also no redundancy. If the Hetzner datacenter has an outage, or the VM crashes, the platform is offline.
- Data Durability: All data lives on a single NVMe drive. Hardware failures happen. Without replication, a drive failure means potential data loss.
- Availability: No hot standby. Recovery time is measured in minutes (Ansible re-provisioning), not milliseconds.
Our Mitigations
This is an R&D platform, not a trading system. We've accepted these trade-offs deliberately, but we haven't ignored them:
- Daily Backups to Object Storage: Critical Delta Lake snapshots are pushed to Hetzner's Object Storage (S3-compatible) on a daily schedule. Worst-case data loss is 24 hours.
- Ansible-based Disaster Recovery: The entire VM can be reprovisioned from scratch in under 10 minutes. All configuration is code. We lose state, not capability.
- Idempotent Pipelines: Dagster assets are designed to be fully recomputable from source. Raw data is immutable. We can rebuild Silver/Gold layers from Bronze.
- Monitoring & Alerting: Basic uptime monitoring via external health checks catches issues before they become prolonged outages.
Reality Check: For production-critical workloads requiring 99.99% uptime and zero data loss, you'd need replicated storage, multi-node deployments, and probably a managed database. The cost equation changes at that point - but so does the complexity budget.
Why Hetzner Cloud? The Economics of Compute
A reasonable question: "Why not just use AWS/GCP/Azure?"
The answer is brutally simple: price-performance ratio for standard VMs.
| Provider | Comparable Spec (4 vCPU, 8GB RAM) | Monthly Cost |
|---|---|---|
| Hetzner CAX21 | ARM64, NVMe storage | ~€6/month |
| AWS t3.medium | x86, EBS storage | ~€35-45/month |
| Azure B2s | x86, Standard SSD | ~€35-40/month |
| GCP e2-medium | x86, Standard PD | ~€30-40/month |
For workloads that don't need global edge distribution, managed Kubernetes, or deep integration with proprietary ML services - the hyperscalers are simply overpriced. Hetzner gives us:
- 5-7x cost reduction for equivalent compute
- Excellent EU datacenters (GDPR compliance baked in)
- No egress fees (a hidden killer on AWS/GCP)
- Bare-metal options for future vertical scaling
The trade-off? No managed services. No click-to-deploy Kubernetes. No IAM federation out of the box. For a team comfortable with Linux and Ansible, that's not a problem - it's a feature.
Future Scalability: The Road Ahead
This architecture is intentionally designed to scale when needed, not before:
-
Object Storage Decoupling: The Delta Lake can be migrated to S3-compatible object storage (Hetzner, MinIO, or even AWS S3) when local NVMe capacity is exceeded. DuckDB and Dagster both support remote Delta tables natively.
-
Multi-Node Compute: If processing demands exceed single-node capacity, we can introduce DuckDB's upcoming distributed mode, or pivot to a lightweight Spark cluster. The medallion architecture remains unchanged.
-
Read Replicas: For serving dashboards or analytics APIs, a read-replica pattern (sync Delta to a second VM) provides horizontal scaling without architectural surgery.
-
Managed Migration Path: If the project graduates to production-critical status, the entire data model (Delta Lake + dbt transformations) ports cleanly to Databricks or Snowflake. We're not locked in - we're deliberately choosing to stay lean.
The Philosophy: Scale when you have the problem, not before. Premature optimization for scale you don't need is just cloud vendors extracting rent from your fear of future growth.
Key Outcomes
- High Efficiency: Achieved full operational data capabilities on a standard 8GB RAM VM, reducing infrastructure costs by >90% compared to managed SaaS.
- High Performance: Capable of processing full Nasdaq/NYSE historical datasets in-memory using DuckDB.
- Ownership: Complete data sovereignty with zero vendor lock-in.
QuantLens proves that with the right architecture, creating a "Data Lakehouse" is a matter of smart engineering and choosing the right tool for the scale, not just buying the most expensive enterprise license.