AI Shopping Assistant
A smarter product search that understands what you mean, not just what you type. Like asking a friend for recommendations.
Context: This project served as a Pre-Seed Validation PoC for Alfee, backed by an established European player (20+ years in business), developed to demonstrate technical feasibility and user engagement for investor fundraising.
This platform solves a common frustration: traditional product search fails when you know what you want but struggle to describe it in keywords. Instead of typing "bluetooth headphones noise cancelling under 100", you can simply say "find me quiet headphones for my commute that won't break the bank".
The challenge was not just technical ("can we build it?") but existential ("can we build it fast, cheap, and good?"). We led the entire product lifecycle, from Pre-Seed strategy to Staff-level architecture and high-fidelity UX.
The result was a high-quality, multi-platform PoC delivered in 4 weeks. It was fully deployed, enabling the client to successfully demo to investors and validate the core concept.
Native iOS app with real-time product recommendations
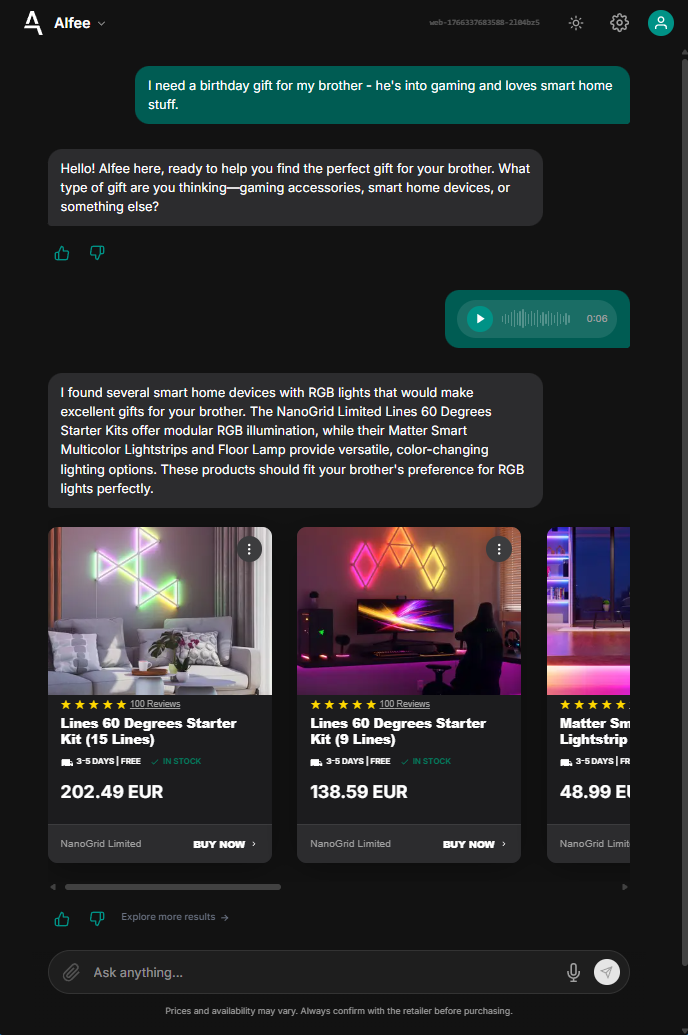
Web interface featuring dark mode and voice input - using OpenAI Whisper for real-time multilingual transcription
🧠 The "Ready-for-Search" Decision Engine
The core UX failure in AI shopping assistants is the "Interrogation Loop." Poorly designed agents ask endless clarifying questions ("What is your budget?", "Do you prefer blue or red?") before showing products.
We engineered a Feature Classification Engine to break this loop by balancing two vectors: Confidence and Specificity.
- Descriptive Features ("Vibes"): Queries like "cozy," "minimalist," or "aggressive design" are routed to Vector Search (semantic understanding).
- Actionable Features ("Constraints"): Hard constraints like "under €200" or "Sony" are extracted into SQL predicates.
The system treats every user query as "Ready-for-Search" by defaulting to a Broad Match Fallback. If the strict SQL filters return zero results, the engine automatically relaxes the constraints while preserving the Vector ranking. This "Two-Variable Pattern" ensures the user always sees relevant inventory, solving the "Empty State" abandonment problem.
⚡ Logic Density: The "Code Writer" Pattern
Standard "Tool-Calling" agents suffer from Linear Chaining Latency. A simple request like "Find a quiet mechanical keyboard under €100 for Mac" typically triggers a ping-pong of 4-5 roundtrips:
Search → (Wait) → Read Results → (Wait) → Filter Price → (Wait) → Filter OS → (Wait) → Final Answer.
We replaced this with a Code Generation Architecture that compiles user intent into a single deterministic Python script.
The "One-Turn" Execution Model
Instead of asking the LLM to perform the logic, we ask it to write the logic.
- Compiler Node (Mistral Large): Analyzes the intent and writes a Python script importing a secure
toolsSDK. - Sandboxed Runtime: The script executes in a hardened Docker container with strict namespace whitelisting - only whitelisted safe modules (like
jsonand the custom tools SDK) are permitted, withos,sys, and network access explicitly forbidden. It performs the vector search, applies complex in-memory filtering, and aggregates results with native Python execution speed. - Result: This achieves an 80%+ reduction in Inference Turn Count. What used to be 5 expensive LLM calls is now 1 call + 1ms of Python execution.
This pattern has since been validated by Anthropic in their article Code Execution with MCP, which documents similar efficiency gains when agents write code instead of chaining tool calls.
❌ Standard MCP Agent Tool Pattern:
✅ Our Code Writer (Compiled):
Hybrid Search Implementation
The generated code leverages a Hybrid Search Strategy effectively:
- SQL handles the Science (hard filters:
price < 100,brand = Keychron). - pgvector handles the Art (semantic intent:
embedding <=> 'quiet typing sound').
This logic executes within the same database transaction, ensuring consistent results without the "context bloat" of feeding 1,000 raw product rows back into the LLM.
Global Multilingual State
We built a "Sticky Language" protocol directly into the LangGraph state machine to support French, English, and Portuguese.
- The Problem: Neutral queries (e.g., "Nike Air Max") often cause stateless classifiers to default back to English, jarring the user experience.
- The Solution: We "locked" the language preference in the global session state. This context persists across all agent nodes, ensuring a consistent native-feeling conversation even during complex reasoning loops.
Infrastructure Efficiency (PgBouncer)
To handle the concurrency of thousands of agents (each potentially opening multiple DB connections), we bypassed standard Postgres limits using PgBouncer in Transaction Mode.
- The Constraint: Postgres connections are memory-heavy (~10MB/conn). A standard instance chokes at ~100 active clients.
- The Unlock: By multiplexing connections at the transaction level (rather than the session level), we successfully served 2,000+ concurrent agents on a single €20/mo instance. This is a massive Unit Economics win, proving you don't need venture capital to scale.
📉 The Math of Trust
We moved from "vibes-based" testing to Production-Grade QA, treating the LLM as a deterministic software component.
Automated Intelligence QA (DeepEval)
We enforced a "Quality Gate" in the CI/CD pipeline using LLM-as-a-Judge metrics. Every Pull Request runs against 50+ "Golden Scenarios" (e.g., "Find a red dress under €50").
- Answer Relevancy > 0.7: Does the answer actually help the user?
- Faithfulness > 0.9: Is the answer supported by the retrieved data? This ensures the system doesn't regress into "hallucination mode" as we optimize the code writer prompts.
Read more about our LLMOps AI Testing methodology here.
The Native Signal (iOS)
We chose SwiftUI not for the ecosystem, but for Trust. In the "Quality" era of AI, Perceived Latency is the only metric that matters.
- Haptics: The subconscious "thud" when a product card snaps into place signals heft and reality.
- 60fps Streaming: By coupling Server-Sent Events (SSE) directly to the SwiftUI state engine, users see the agent "thinking" in real-time. This turns a 10-second wait (latency) into a 10-second "observation" of work being done (value), fundamentally changing the user's trust equation.
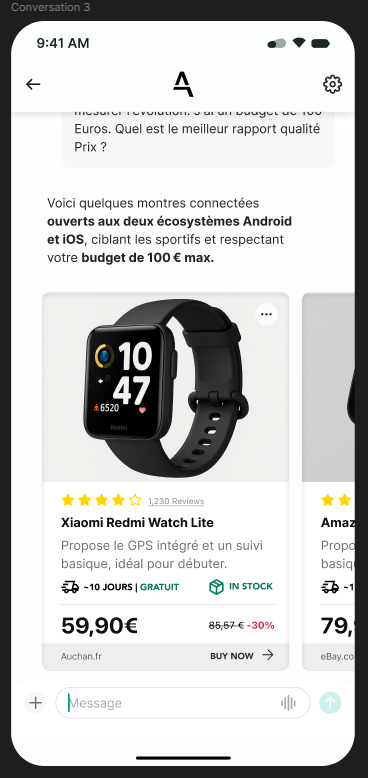
This project was delivered end-to-end as a solo engineer engagement - from architecture through deployment. Questions about this implementation? Get in touch.
— Pedro
Founder & Principal Engineer